Python 笔记
这篇笔记是看《Python编程从入门到实践》的基础部分时记录的,主要是一些常见的知识点,奈何自己脑子不好使,只能烂笔头弥补一下,可以当做自己的知识点查询工具,后续应该还会继续更新,会不会另起一篇就好说啦~总之,如果有错误的地方,还请指出,谢谢!!!
字符操作
string.title():将字符串的第一个字符变成大写
string.upper():将字符串全部变成大写
string.lower():将字符串全部变成小写
pring():打印
Python使用加号(+)来合并字符串
制表符:\t —> print(“\tpython”)
换行符:\n

string.lstrip():删除字符串前的空格
string.rstrip():删除字符串后的空格
单引号间不能单独加一个单引号,会报错,Python不能识别
双引号间可以加一个单引号,不会报错,Python能识别
两个乘号表示乘方运算:3**3⇒27
空格不影响计算表达式的方式
浮点数运算结果包含的小数位数是不确定的

str():可以将非字符串表示为字符串的函数
python2中除法会将小数部分直接删除,保留整数
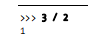

python3的除法得到的结果则是浮点型的
python使用井号(#)作为注释标识
import this:这段命令会调用出 Tim Peters 的Python之禅
python使用方括号( [ ] )表示列表,使用逗号分隔元素

python访问列表的最后一个元素,可以使用索引 -1 ,以此类推

添加新的元素在列表中:列表名.append( ‘元素’ ),会自动添加到末尾
插入元素到列表中:列表名.insert(位置,’元素’ ),插入位置及之后的元素全部向后自动移一位
删除列表中的元素:
- del 列表名 [ 索引 ] ,删除索引位置的元素,后面的元素会自动补上
- 使用 列表名.pop()可以将列表末尾的元素弹出(出栈操作)
- 根据值删除元素:列表名.remove( ‘ 值 ‘ ),该方法只能删除列表中的第一个相同值得元素
列表名.sort():自动对列表进行永久性的排序(升序);
列表名.sort(reverse=True):自动对列表进行永久的排序(降序);
sorted(列表名):自动对列表进行临时排序(升序);
sorted(列表名,reverse=True):自动对列表进行临时排序(降序);
列表名.reverse():自动进行永久性翻转列表元素的排序顺序,再次使用即可翻转回来;
len(列表名):获取列表的长度;
遍历整个列表(类foreach):

Range(start,end,步长):
生成从start到(end-1)的整数列表,(左闭右开结构);
start默认从零开始,每次增加步长的值,直到达到或大于end值时结束;
当start>end时,如果start+步长>start,则无返回值,反之则有;
使用C#进行功能实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29public static List<int> Range(int start,int end,int len) {
List<int> range = new List<int>();
if (start < end)
{
for (int i = start; i < end; i += len)
{
range.Add(i);
}
}
else if (start > end)
{
for (int i = start; i > end; i += len)
{
if (i + len < i)
{
range.Add(i);
}
else
{
break;
}
}
}
else {
range.Add(0);
}
return range;
}
min(列表名):获取列表的最小值;
max(列表名):获取列表的最大值;
sum(列表名):获取列表值得总和;
列表解析:
- 将for循环和创建新元素的代码合并成一行,并自动附加新的元素;
- for循环后面没有冒号( : )
1 | squares = [value**2 for value in range(1,11)] |
处理列表的部分元素——Python称之为切片:
- 列表名[start:end]:获取列表从索引start开始到索引(end-1)位置的元素
- start默认从0开始,end默认为列表的长度
- 单写一边的时候,则代表从单写的一端与另一端默认之间的元素
- 可以写负数,负数的作用与概念为列表中负数的概念
复制列表:
使用省略头尾索引的切片
1
2players=['charles','martina','michael','florence','eli']
otherPlayers=players[:]如果不使用切片,而是直接赋值,则无法得到两个列表
1
otherPlayers=players
直接赋值的方式,不是将列表 players 的副本存储到 otherPlayers里,而是让Python将新变量 otherPlayers 关联到包含在 players 中的列表,因此这两个变量都是指向同一个列表
元组:
不可变的列表成为元组
使用圆括号( ( ) )进行标识
1
dimension=(0,1,2,3,4,5)
访问方式与列表相同,但是无法对元组的元素进行赋值
修改元组的方法即重定义一次元组的所有元素
if语句:
1 | cars=['audi','bmw','subaru','toyota'] |
- Python检查是否相等时,区分大小写
- 使用 and 作为连接符(与),进行多个条件进行检查
- 使用 or 作为连接符(或),进行多个条件进行检查
- 使用 in 关键字,判断特定值是否已包含在列表中,返回一个bool值
- ‘ 关键字 ‘ in 列表名
- 使用 not in 关键字,判断特定值是否不包含在列表中,返回一个bool值
if-else语句:
1 | age=19 |
if-elif-else语句:
1 | age =12 |
如果只想执行一个代码块,就使用 if-elif-else 结构;如果要运行多个代码块,就使用一系列独立的 if 语句
字典:
- 使用花括号填装内容,使用冒号进行键—值对应,键用引号



- 字典是一种动态结构,可以随时在其中添加键—值对
- 键—值对的排列顺序与添加顺序不同

使用 del 关键字进行删除,必须指定字典名和要删除的键
- del 字典名[ ‘键’ ]
遍历字典:
items( )方法会返回一个键—值对列表:for 存键的变量名,存值得变量名 in 字典名.items( ):
keys( )方法会返回键:for 存键的变量名 in 字典名.keys( ):
遍历字典时,默认遍历所有的键,遍历键的时候可以不写keys( )方法,会隐式实现
values( )方法会返回一个值列表:for 存值得变量名 in 字典名.values( ):
这个方法不会剔除重复项,可以使用集合(set)来剔除列表中的重复项
for 存值的变量名 in set(字典名.values( ))
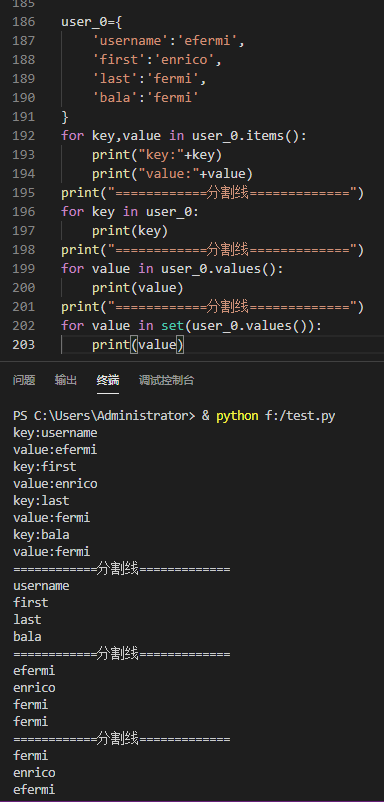
嵌套:将一系列字典存储在列表中,或将列表作为值存储在字典里
字典列表:

列表和字典的嵌套层级不应该太多
可以在字典中嵌套字典,但是这样做可能会导致代码很快复杂起来
用户输入与求模运算
input ( ) 输入:
函数 input ( ) 会让程序暂停运行,等待用户输入一些文本,获取用户的输入后,Python会将其存储在一个变量中

int ( ) 输入:
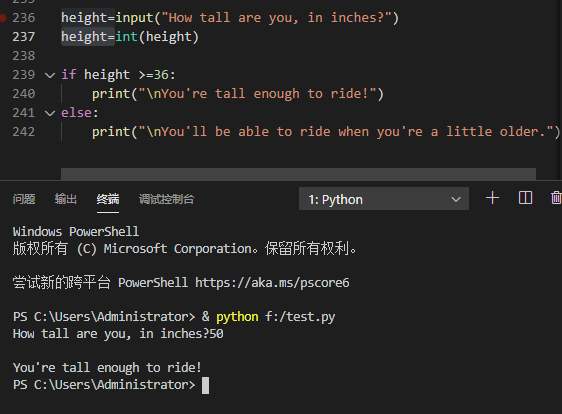
求模运算符:%

Python3和2中用户输入的区别:

While循环:
while 条件:循环体 —— 条件为真则继续执行循环体
1
2
3
4
5
6
7
8
9
10value=5
while value>0:
print(value)
value-=1
#----------------
5
4
3
2
1Python首次运行while语句时,会先执行条件判断,但此时用户还没有输入,这回导致报错,所有必须要给用来做条件判断的变量一个初始值,即便是一个空字符串,但也是符合要求的
标志:在要求很多条件都满足才能继续运行的程序中,定义一个变量,用于判断整个程序是否处于活动状态,这个变量就是标志
break:使用break语句可以立即跳出当前循环,列表或字典的for循环均可使用
continue:使用continue语句会立即结束本次循环
不应该使用for循环在列表的遍历中进行修改,否则会导致Python难以跟踪其中的元素
可以使用while循环在遍历列表的同时进行修改
列表间移动元素:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23unconfirmed_users = ['alice','brian','candace']
confirmed_users = []
while unconfirmed_users:
current_user = unconfirmed_users.pop()
print("Verifying user:" + current_user.title())
confirmed_users.append(current_user)
print("\nThe following users have been confirmed:")
for confirmed_user in confirmed_users:
print(confirmed_user.title())
"""
Verifying user:Candace
Verifying user:Brian
Verifying user:Alice
The following users have been confirmed:
Candace
Brian
Alice
"""
函数
定义函数:
def 关键字:定义函数名

def 函数名(函数为完成其任务需要什么样的信息):
紧跟其后的所有缩进行构成了函数体
实参和形参

- 形参:username
- 实参:’ jesse ‘
- 调用函数时,将实参传递给函数,存储在形参中
传递实参
位置实参:实参的顺序与形参的顺序相同
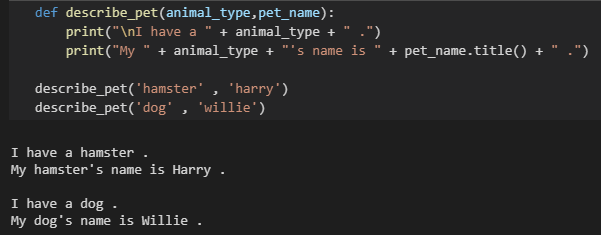
- 位置实参的顺序很重要
关键字实参:每个实参都有变量名和值组成
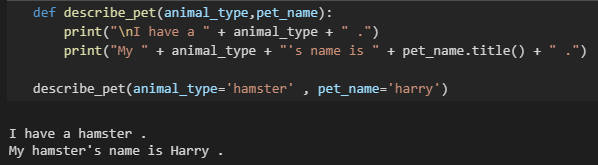
- 传递给函数名称-值对,直接在实参中将名称和值关联起来
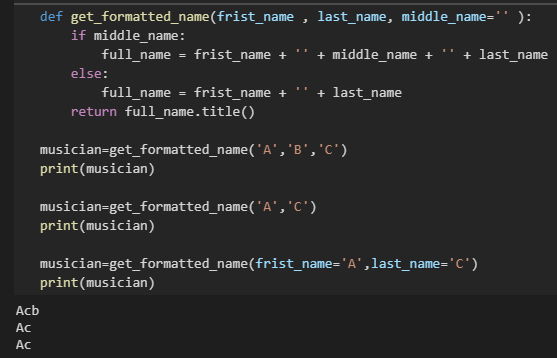
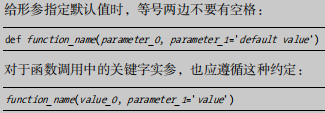
使用默认值时,在形参列表中必须先列出没有默认值的形参,再列出默认值的实参。
返回值:函数可以返回任何类型的值
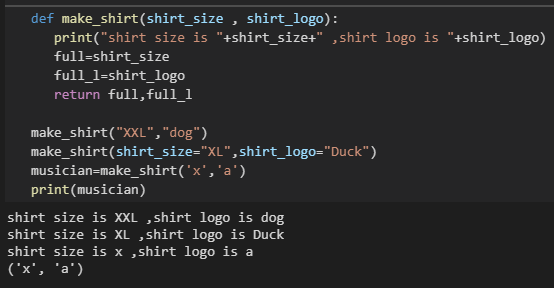
返回字典
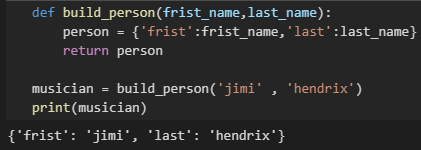
让实参变为可选的:
- 非默认实参(可选参数)必须放在默认实参(必填参数)后面
在函数中对列表进行的任何修改都是永久性的
传递任意数量的实参
- Python允许函数从调用语句中收集任意数量的实参
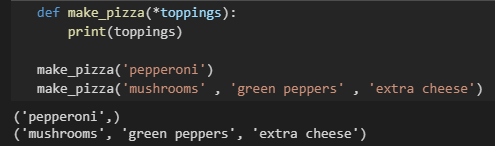
toppings:一个星号()让 Python 创建一个名为 toppings 的空元组,收到所有值都会封装到这个元组中,即便只收到一个值也是如此
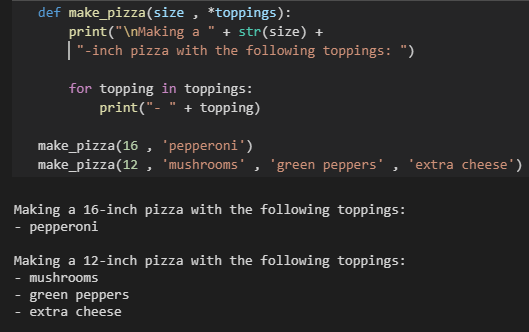
如果要让函数接受不同类型的实参,必须在函数定义中,将接纳任意数量实参的形参放在最后
Python 先匹配 位置实参 和 关键字实参,再将余下的实参都收集到最后一个形参中
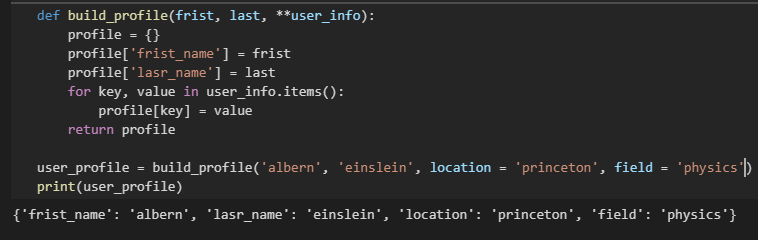
****user_info:形参 **user_info 中的两个星号()让 Python 创建一个名为 user_info 的空字典
将函数存储在模块中
import 语句允许在当前运行的程序文件中使用模块中的代码
模块的扩展名为 .py 的文件
导入模块中特定函数的语法

from 模块名 import 函数名,函数名

若是使用这种语法,调用函数时就无需使用点( . )进行引用
为了防止导入的函数的名称冲突或太长,可以使用 as 指定别名
from 模块名 import 函数名 as 别名

from 模块名 as 别名

使用星号( * )运算符可以让 Python 导入模块中的所有函数
from 模块名 import*

无需使用点即可调用函数,尽量少用,容易出现重名、覆盖等问题
类
首字母大写的名称指的是类

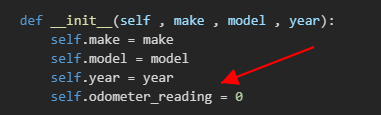
方法 init( ):这是一个特殊的方法
- 开头和末尾各有的两个下划线是一种约定,为了避免命名冲突
- 形参 self 是必不可少的,且必须位于其他形参前面
- 调用该方法时会自动传入实参 self ,它是指向实例本身的引用,让实例能够访问类中的属性和方法
- self 会自动传递,所有我们不需要传递它,创建实例的时候只需要给其他形参提供值
- 通过实例访问的变量称为 属性: self.name = name 获取存储在形参 name 中的值,将其存储到变量 name 中 ,然后该变量被关联到当前创建的实例。
类中的每个属性都必须有初始值
在方法__init()__内指定这种初始值是可行的
如果对某个属性这样做了,酒无需包含为它提供初始值的形参
修改属性的值有三种不同的方法
直接通过实例进行修改

通过方法进行设置

通过方法进行递增(增加特定的值)

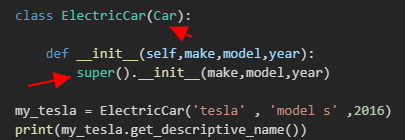
创建子类的实例时,Python需要先完成的任务是给父类的所有属性赋值
继承的方式
父类必须包含在当前文件中,且位于子类前面
必须在括号内指定父类的名称
父类也成为 超类(superclass)
Python2.7中的区别

处理文件
从文件中读取数据
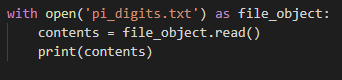
- open(要打开的文件名):Python 在当前执行的文件所在的目录中查找指定的文件,并返回一个表示文件的对象
- 关键字 with:在不需要访问文件后将其关闭;Python会在合适的时候自动关闭文件,所以最好不要过早的使用 close()
- read():读取文件并转换为字符串,在到达文件末尾的时候会返回一个空字符串
文件路径
相对文件路径

绝对文件路径

逐行读取
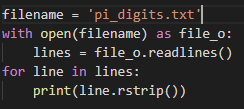
- readlines():从文件中读取每一行并存储在一个列表中
- string[ start : end ]:取字符串从 start 到 end 位之间的字符
- Python 的字符串if判断会自动帮你匹配你输入的字符串,例如在圆周率中查生日
写入空文件
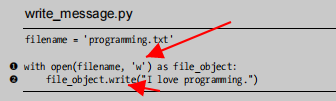
open(要打开的文件的名称,告诉Python我们要以写入模式打开这个软件)
读取模式( ‘ r ’ ),写入模式( ‘ w ’ ),附加模式( ‘ a ’ )
读取和写入模式( ‘ r+ ’)
如果不写,默认是只读模式
write():将一个字符串写入文件
- Python 只能将字符串写入文本文件
- write 不会自动换行,所有需要我们自己添加换行符——“\n”
附加模式打开时,写入的文件都将添加到文件末尾,如果指定的文件不存在,Python 将会创建一个空文件
异常
异常时 Python 用来管理程序执行期间发生的错误的特殊对象
如果没有对异常进行处理,程序将停止,并显示一个 traceback ,其中包含有关异常的报告
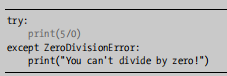
使用 try - except 代码块处理异常
ZeroDivisionError 异常:当Python无法按你的要求做时,就会创建这种对象,这种情况下Python会停止运行并指出引发了哪种异常
将可能发生异常的代码放在 try 内,将处理方式放在 except 内
这样就不会因为异常而导致程序停止运行
一些只需要在 try 中执行的代码可以放在 else中
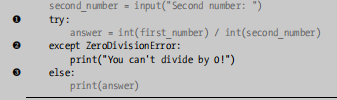
FileNotFoundError 异常:找不到文件
pass:可以在代码块中使用它让 Python 什么都不要做,可以充当占位符,提醒你在程序的某个地方什么都没做
Json模块(存储数据)
json.dump():接受两个实参,要存储的数据以及可用于存储数据的文件对象

json.load():参数为需要读取数据的文件对象

json.dumps():将字 典类 型转化为 字符串 类型
json.loads():将 字符串 类型转化成 字典 类型
json.dump():将 字典 类型转化为 字符串 类型
json.load():读取 Json 里的数据
重构:将代码划分为一系列完成具体工作的函数,这个过程就被称为 重构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30import json
def get_stored_likeNum():
"""如果存储了用户喜欢的数字,就获取它"""
filename = 'likeNum.json'
try:
with open(filename) as f_obj:
likeNum = json.load(f_obj)
except FileNotFoundError:
return None
else:
return likeNum
def get_new_likeNum():
"""提示用户输入喜欢的数字"""
likeNum = input("What is your like number?")
filename = 'likeNum.json'
with open(filename, 'w') as f_obj:
json.dump(likeNum , f_obj)
return likeNum
def greet_num():
likeNum = get_stored_likeNum()
if likeNum:
print("I know your favorite number! It's:" + likeNum + "!")
else:
likeNum = get_new_likeNum()
print("We'll remember you like number, " + likeNum + "!")
greet_num()
测试代码
测试函数
单元测试和测试用例:
- Python 标准库中的模块 unittest 提供了代码测试工具。
- 单元测试:用于核实函数的某个方面没有问题
- 测试用例:是一组单元测试,这些单元测试一起核实函数在各种情况下的行为都符合要求
- 全覆盖式测试:用例包含一整套单元测试,涵盖了各种可能的函数使用方式
可以通过的测试:
先导入模块 unittest 以及要测试的函数,再创建一个继承unittest.TestCase 的类,并编写一系列对函数不同行为的不同方面进行测试

在①处,创建了一个类,并且继承了 unittest.TestCase
在运行这个脚本的时候,所有以 test_ 打头的方法都将自动运行
unittest 类最有用的功能之一:一个断言方法( assertEqual())
- 这个方法就是将测试的结果与预期的结果放入其中,如果相同则成功
代码 unittest.main() 让Python运行这个文件中的测试
不能通过的测试:

测试类
各种断言方法

方法 setUp()
- 如果你在 TestCase 类中包含了方法 setUp ( ) ,Python 将先运行它,再运行各个以 test_ 打头的方法


